| 10个用于可解释AI的Python库 | 您所在的位置:网站首页 › lime explainer python › 10个用于可解释AI的Python库 |
10个用于可解释AI的Python库
|
XAI的目标是为模型的行为和决定提供有意义的解释,本文整理了目前能够看到的10个用于可解释AI的Python库 什么是XAI?XAI,Explainable AI是指可以为人工智能(AI)决策过程和预测提供清晰易懂的解释的系统或策略。 XAI 的目标是为他们的行为和决策提供有意义的解释,这有助于增加信任、提供问责制和模型决策的透明度。 XAI 不仅限于解释,还以一种使推理更容易为用户提取和解释的方式进行 ML 实验。 在实践中,XAI 可以通过多种方法实现,例如使用特征重要性度量、可视化技术,或者通过构建本质上可解释的模型,例如决策树或线性回归模型。 方法的选择取决于所解决问题的类型和所需的可解释性水平。 AI 系统被用于越来越多的应用程序,包括医疗保健、金融和刑事司法,在这些应用程序中,AI 对人们生活的潜在影响很大,并且了解做出了决定特定原因至关重要。因为这些领域的错误决策成本很高(风险很高),所以XAI 变得越来越重要,因为即使是 AI 做出的决定也需要仔细检查其有效性和可解释性。 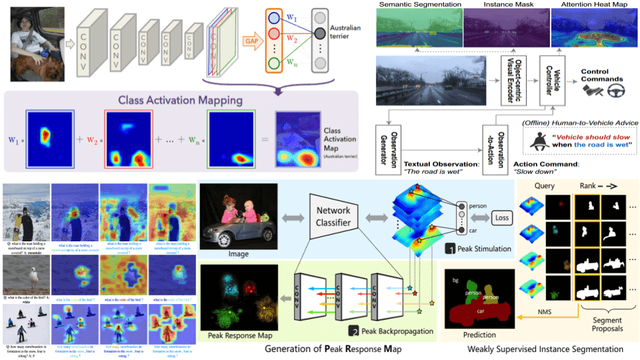 可解释性实践的步骤
可解释性实践的步骤
数据准备:这个阶段包括数据的收集和处理。 数据应该是高质量的、平衡的并且代表正在解决的现实问题。 拥有平衡的、有代表性的、干净的数据可以减少未来为保持 AI 的可解释性而付出的努力。 模型训练:模型在准备好的数据上进行训练,传统的机器学习模型或深度学习神经网络都可以。 模型的选择取决于要解决的问题和所需的可解释性水平。 模型越简单就越容易解释结果,但是简单模型的性能并不会很高。 模型评估:选择适当的评估方法和性能指标对于保持模型的可解释性是必要的。 在此阶段评估模型的可解释性也很重要,这样确保它能够为其预测提供有意义的解释。 解释生成:这可以使用各种技术来完成,例如特征重要性度量、可视化技术,或通过构建固有的可解释模型。 解释验证:验证模型生成的解释的准确性和完整性。 这有助于确保解释是可信的。 部署和监控:XAI 的工作不会在模型创建和验证时结束。 它需要在部署后进行持续的可解释性工作。 在真实环境中进行监控,定期评估系统的性能和可解释性非常重要。 1、SHAP (SHapley Additive exPlanations)SHAP是一种博弈论方法,可用于解释任何机器学习模型的输出。它使用博弈论中的经典Shapley值及其相关扩展将最佳信用分配与本地解释联系起来。 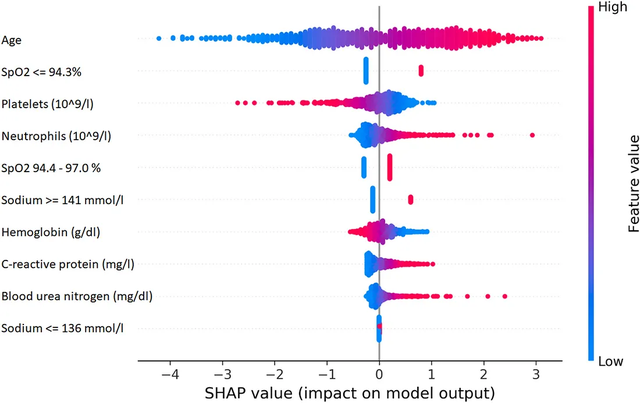 2、LIME(Local Interpretable Model-agnostic Explanations)
2、LIME(Local Interpretable Model-agnostic Explanations)
LIME 是一种与模型无关的方法,它通过围绕特定预测在局部近似模型的行为来工作。 LIME 试图解释机器学习模型在做什么。LIME 支持解释文本分类器、表格类数据或图像的分类器的个别预测。 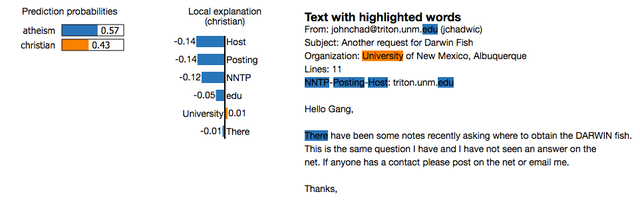 3、Eli5
3、Eli5
ELI5是一个Python包,它可以帮助调试机器学习分类器并解释它们的预测。它提供了以下机器学习框架和包的支持: scikit-learn:ELI5可以解释scikit-learn线性分类器和回归器的权重和预测,可以将决策树打印为文本或SVG,显示特征的重要性,并解释决策树和基于树集成的预测。ELI5还可以理解scikit-learn中的文本处理程序,并相应地突出显示文本数据。 Keras -通过Grad-CAM可视化解释图像分类器的预测。 XGBoost -显示特征的重要性,解释XGBClassifier, XGBRegressor和XGBoost . booster的预测。 LightGBM -显示特征的重要性,解释LGBMClassifier和LGBMRegressor的预测。 CatBoost:显示CatBoostClassifier和CatBoostRegressor的特征重要性。 lightning -解释lightning 分类器和回归器的权重和预测。 sklearn-crfsuite。ELI5允许检查sklearn_crfsuite.CRF模型的权重。 基本用法: Show_weights() 显示模型的所有权重,Show_prediction() 可用于检查模型的个体预测 
ELI5还实现了一些检查黑盒模型的算法: TextExplainer使用LIME算法解释任何文本分类器的预测。排列重要性法可用于计算黑盒估计器的特征重要性。 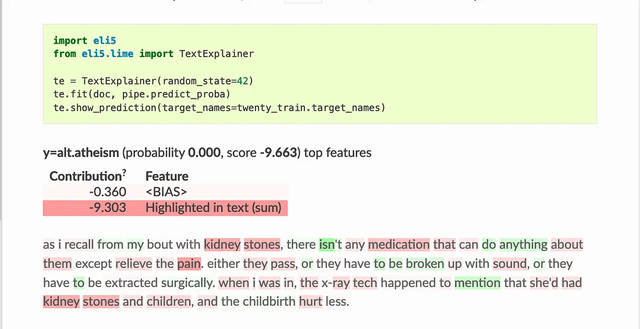 4、Shapash
4、Shapash
Shapash提供了几种类型的可视化,可以更容易地理解模型。通过摘要来理解模型提出的决策。该项目由MAIF数据科学家开发。Shapash主要通过一组出色的可视化来解释模型。 Shapash通过web应用程序机制工作,与Jupyter/ipython可以完美的结合。 from shapash import SmartExplainer xpl = SmartExplainer( model=regressor, preprocessing=encoder, # Optional: compile step can use inverse_transform method features_dict=house_dict # Optional parameter, dict specifies label for features name ) xpl.compile(x=Xtest, y_pred=y_pred, y_target=ytest, # Optional: allows to display True Values vs Predicted Values ) xpl.plot.contribution_plot("OverallQual") 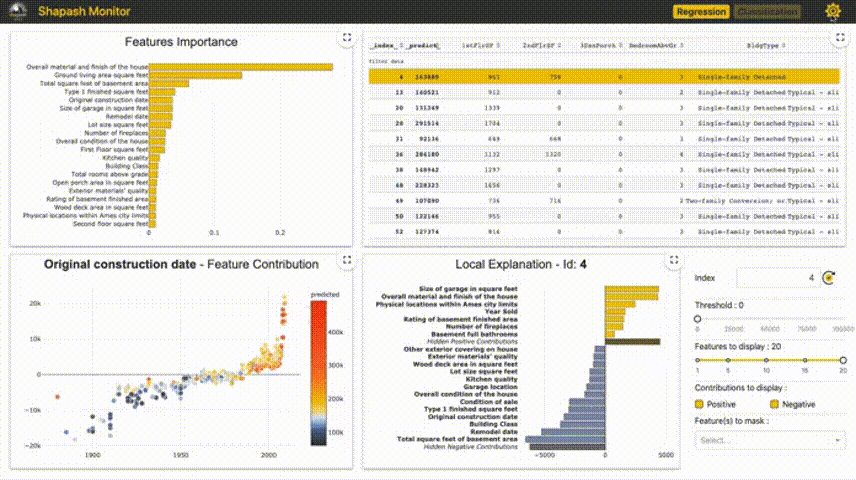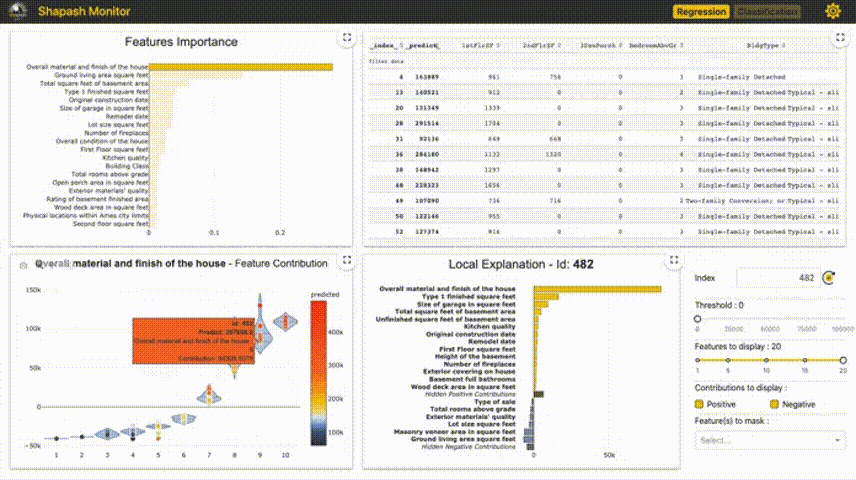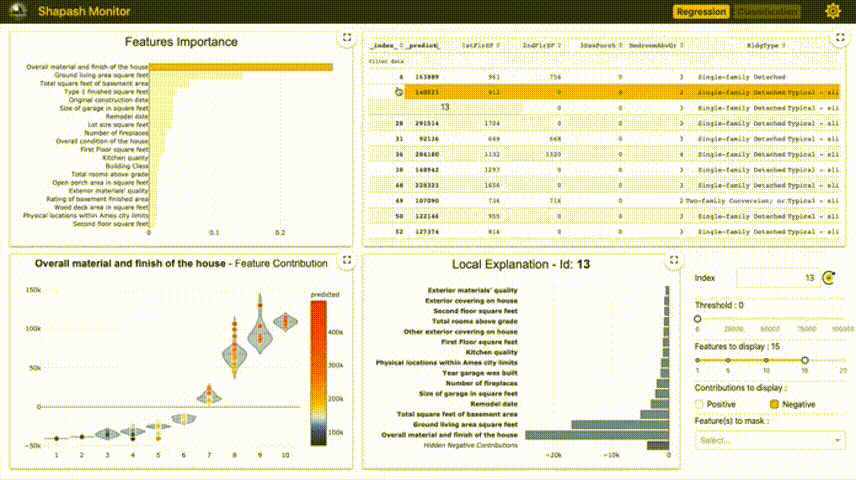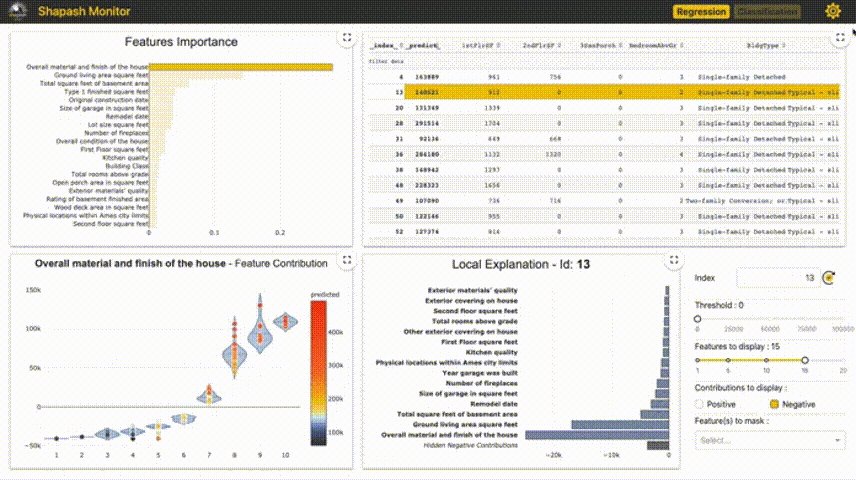 5、Anchors
5、Anchors
Anchors使用称为锚点的高精度规则解释复杂模型的行为,代表局部的“充分”预测条件。 该算法可以有效地计算任何具有高概率保证的黑盒模型的解释。 Anchors可以被看作为LIME v2,其中LIME的一些限制(例如不能为数据的不可见实例拟合模型)已经得到纠正。Anchors使用局部区域,而不是每个单独的观察点。它在计算上比SHAP轻量,因此可以用于高维或大数据集。但是有些限制是标签只能是整数。 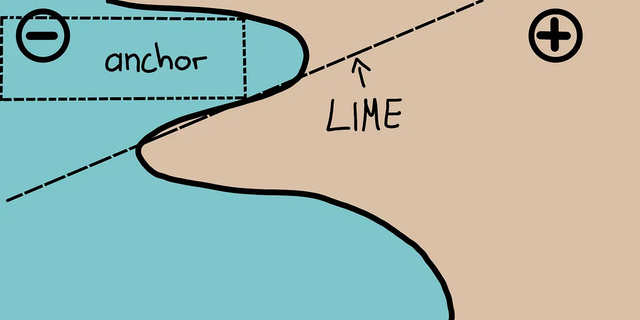 6、BreakDown
6、BreakDown
BreakDown是一种可以用来解释线性模型预测的工具。它的工作原理是将模型的输出分解为每个输入特征的贡献。这个包中有两个主要方法。Explainer()和Explanation() model = tree.DecisionTreeRegressor() model = model.fit(train_data,y=train_labels) #necessary imports from pyBreakDown.explainer import Explainer from pyBreakDown.explanation import Explanation #make explainer object exp = Explainer(clf=model, data=train_data, colnames=feature_names) #What do you want to be explained from the data (select an observation) explanation = exp.explain(observation=data[302,:],direction="up") 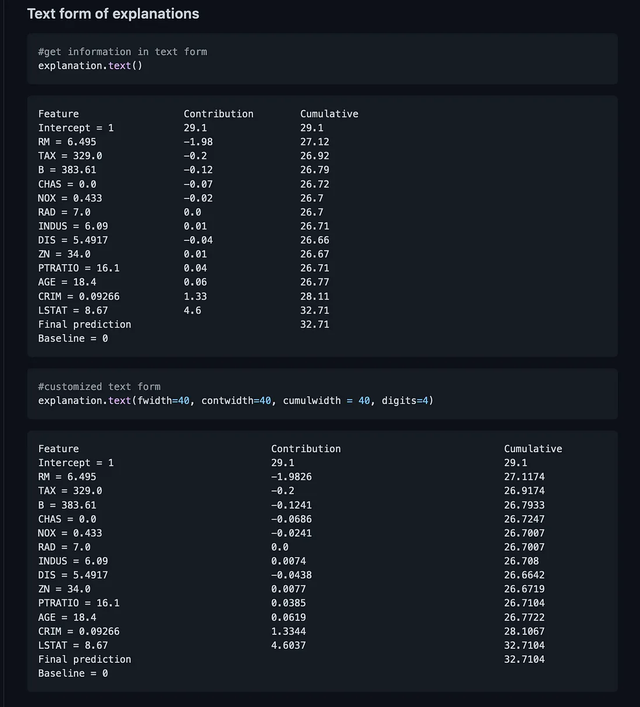 7、Interpret-Text
7、Interpret-Text
Interpret-Text 结合了社区为 NLP 模型开发的可解释性技术和用于查看结果的可视化面板。 可以在多个最先进的解释器上运行实验,并对它们进行比较分析。 这个工具包可以在每个标签上全局或在每个文档本地解释机器学习模型。 以下是此包中可用的解释器列表: Classical Text Explainer——(默认:逻辑回归的词袋) Unified Information Explainer Introspective Rationale Explainer 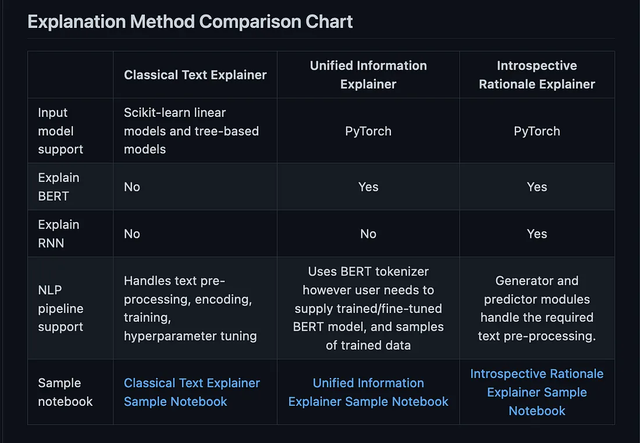
它的好处是支持CUDA,RNN和BERT等模型。并且可以为文档中特性的重要性生成一个面板 from interpret_text.widget import ExplanationDashboard from interpret_text.explanation.explanation import _create_local_explanation # create local explanation local_explanantion = _create_local_explanation( classification=True, text_explanation=True, local_importance_values=feature_importance_values, method=name_of_model, model_task="classification", features=parsed_sentence_list, classes=list_of_classes, ) # Dash it ExplanationDashboard(local_explanantion)  8、aix360 (AI Explainability 360)
8、aix360 (AI Explainability 360)
AI Explainbability 360工具包是一个开源库,这个包是由IBM开发的,在他们的平台上广泛使用。AI Explainability 360包含一套全面的算法,涵盖了不同维度的解释以及代理解释性指标。 
工具包结合了以下论文中的算法和指标: Towards Robust Interpretability with Self-Explaining Neural Networks, 2018. ref Boolean Decision Rules via Column Generation, 2018. ref Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives, 2018. ref Improving Simple Models with Confidence Profiles, , 2018. ref Efficient Data Representation by Selecting Prototypes with Importance Weights, 2019. ref TED: Teaching AI to Explain Its Decisions, 2019. ref Variational Inference of Disentangled Latent Concepts from Unlabeled Data, 2018. ref Generating Contrastive Explanations with Monotonic Attribute Functions, 2019. ref Generalized Linear Rule Models, 2019. ref 9、OmniXAIOmniXAI (Omni explable AI的缩写),解决了在实践中解释机器学习模型产生的判断的几个问题。 它是一个用于可解释AI (XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习功能,并能够解决实践中解释机器学习模型所做决策的许多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、ML研究人员和从业者提供可解释的AI。 from omnixai.visualization.dashboard import Dashboard # Launch a dashboard for visualization dashboard = Dashboard( instances=test_instances, # The instances to explain local_explanations=local_explanations, # Set the local explanations global_explanations=global_explanations, # Set the global explanations prediction_explanations=prediction_explanations, # Set the prediction metrics class_names=class_names, # Set class names explainer=explainer # The created TabularExplainer for what if analysis ) dashboard.show()  10、XAI (eXplainable AI)
10、XAI (eXplainable AI)
XAI 库由 The Institute for Ethical AI & ML 维护,它是根据 Responsible Machine Learning 的 8 条原则开发的。 它仍处于 alpha 阶段因此请不要将其用于生产工作流程。 https://avoid.overfit.cn/post/3215f2fa39554363b983d07f642ce0cb 作者:Mandar Karhade, |
【本文地址】